I’d like to add one more layer to this great explanation.
Usually, this kind of predictions should be made in two steps:
calculate the conditional probability of the next word (given the data), for all possible candidate words;
choose one word among these candidates.
The choice in step 2. should be determined, in principle, by two factors: (a) the probability of a candidate, and (b) also a cost or gain for making the wrong or right choice if that candidate is chosen. There’s a trade-off between these two factors. For example, a candidate might have low probability, but also be a safe choice, in the sense that if it’s the wrong choice no big problems arise – so it’s the best choice. Or a candidate might have high probability, but terrible consequences if it were the wrong choice – so it’s better to discard it in favour of something less likely but also less risky.
This is all common sense! but it’s at the foundation of the theory behind this (Decision Theory).
The proper calculation of steps 1. and 2. together, according to fundamental rules (probability calculus & decision theory) would be enormously expensive. So expensive that something like chatGPT would be impossible: we’d have to wait for centuries (just a guess: could be decades or millennia) to train it, and then to get an answer. This is why Large Language Models do two approximations, which obviously can have serious drawbacks:
they use extremely simplified cost/gain figures – in fact, from what I gather, the researchers don’t have any clear idea of what they are;
they directly combine the simplified cost/gain figures with probabilities;
They search for the candidate with the highest gain+probability combination, but stopping as soon as they find a relatively high one – at the risk of missing the one that was actually the real maximum.
(Sorry if this comment has a lecturing tone – it’s not meant to. But I think that the theory behind these algorithms can actually be explained in very common-sense term, without too much technobabble, as @TheChurn’s comment showed.)

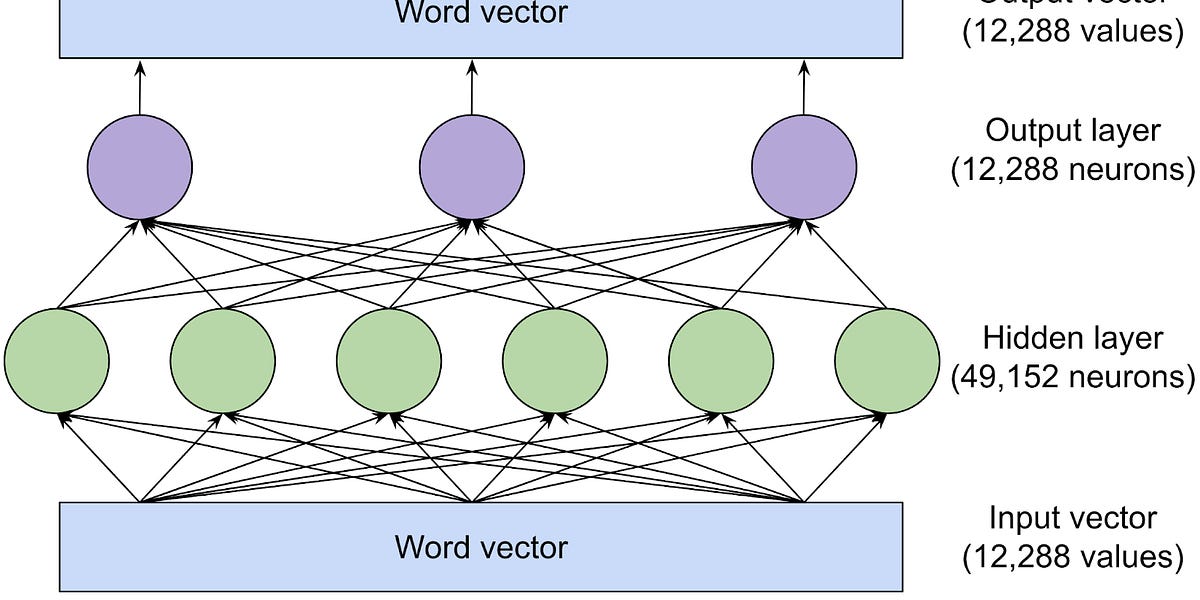
I’d like to add one more layer to this great explanation.
Usually, this kind of predictions should be made in two steps:
calculate the conditional probability of the next word (given the data), for all possible candidate words;
choose one word among these candidates.
The choice in step 2. should be determined, in principle, by two factors: (a) the probability of a candidate, and (b) also a cost or gain for making the wrong or right choice if that candidate is chosen. There’s a trade-off between these two factors. For example, a candidate might have low probability, but also be a safe choice, in the sense that if it’s the wrong choice no big problems arise – so it’s the best choice. Or a candidate might have high probability, but terrible consequences if it were the wrong choice – so it’s better to discard it in favour of something less likely but also less risky.
This is all common sense! but it’s at the foundation of the theory behind this (Decision Theory).
The proper calculation of steps 1. and 2. together, according to fundamental rules (probability calculus & decision theory) would be enormously expensive. So expensive that something like chatGPT would be impossible: we’d have to wait for centuries (just a guess: could be decades or millennia) to train it, and then to get an answer. This is why Large Language Models do two approximations, which obviously can have serious drawbacks:
they use extremely simplified cost/gain figures – in fact, from what I gather, the researchers don’t have any clear idea of what they are;
they directly combine the simplified cost/gain figures with probabilities;
They search for the candidate with the highest gain+probability combination, but stopping as soon as they find a relatively high one – at the risk of missing the one that was actually the real maximum.
(Sorry if this comment has a lecturing tone – it’s not meant to. But I think that the theory behind these algorithms can actually be explained in very common-sense term, without too much technobabble, as @TheChurn’s comment showed.)